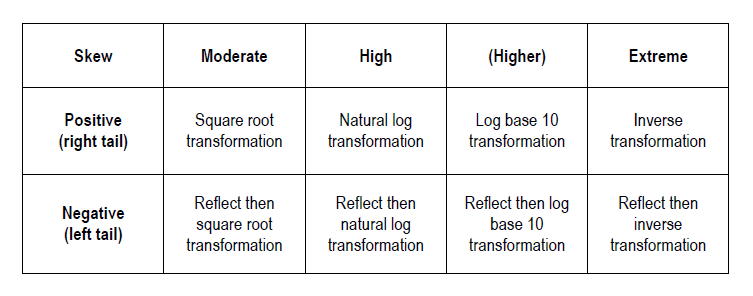
Medical Device Clinical Trials vs Pharmaceutical Clinical Trials – What’s the Difference?
Medical devices and drugs share the same goal – to safely improve the health of patients. Despite this, substantial differences can be observed between the two. Principally, drugs interact with biochemical pathways in human bodies while medical devices can encompass a wide range of different actions and reactions, for example, heat, radiation (Taylor and Iglesias, 2009). Additionally, medical devices encompass not only therapeutic devices but diagnostic devices, as well (Stauffer, 2020).
More specifically medical device categories can include therapeutic and surgical devices, patient monitoring, diagnostic and medical imaging devices, among others; making it a very heterogeneous area (Stauffer, 2020). As such, medical device research spills over into many different fields of healthcare services and manufacturing. This research is mostly undertaken by SME’s ( small to medium enterprises) instead of larger well-established companies as is more predominantly the case with pharmaceutical research. SME’s and start-ups undertake the majority of the early stage device development, particularly where any new class of medical device is concerned, whereas the larger firms get involved in later stages of the testing process (Taylor and Iglesias, 2009).
Classification criteria for medical devices
There are strict regulations that researchers and developers need to follow, which includes general device classification criteria. This classification criterion consists of three classes of medical devices, the higher class medical device the stricter regulatory controls are for the medical device.
- Class I, typically do not require premarket notifications
- Class II, require premarket notifications
- Class III, require premarket approval
Food and Drug Administration (FDA)
Drug licensing and market access approval by the Food and Drug Administration (FDA) and international equivalents require manufacturers to undertake phase II and III randomised controlled trials in order to provide the regulator with evidence of their drug’s efficacy and safety (Taylor and Iglesias, 2009).
Key stages of medical device clinical trials
In general medical device clinical trials are smaller than drug trials and usually start with feasibility study. This provides a limited clinical evaluation of the device. Next a pivotal trial is conducted to demonstrate the device in question is safe and effective (Stauffer, 2020).
Overall the medical device trials can be considered to have three stages:
- Feasibility study,
- Pivotal study to determine if the device is safe and effective,
- Post-market study to analyse the long-term effectiveness of the device.
Clinical evaluation for medical devices
Clinical evaluation is an ongoing process conducted throughout the life cycle of a medical device. It is first performed during the development of a medical device in order to identify data that need to be generated for regulatory purposes and will inform if a new device clinical investigation is necessary. It is then repeated periodically as new safety, clinical performance and/or effectiveness information about the medical device is obtained during its use.(International Medical Device Regulators Forum, 2019)
During the evaluative process, a distinction must be made between device types – diagnostic or therapeutic. The criteria for diagnostic technology evaluations are usually divided into four groups:
- technical capacity
- diagnostic accuracy
- diagnostic and therapeutic impact
- patient outcome
The importance of evaluation
Evaluations provide important information about a device and can indicate the possible risks and complications. The main measures of diagnostic performance are sensitivity and specificity. Based on the results of the clinical investigation the intervention may be approved for the market. When placing a medical device on the market, the manufacturer must have demonstrated through the use of appropriate conformity assessment procedures that the medical device complies with the Essential Principles of Safety and Performance of Medical Devices(International Medical Device Regulators Forum, 2019).The information on effectiveness can be observed by conducting experimental or observational studies.
Post-market surveillance
Manufacturers are expected to implement and maintain surveillance programs that routinely monitor the safety, clinical performance and/or effectiveness of the medical device as part of their Quality Management System (International Medical Device Regulators Forum, 2019). The scope and nature of such post market surveillance should be appropriate to the medical device and its intended use. Using data generated from such programs (e.g. safety reports, including adverse event reports; results from published literature, any further clinical investigations), a manufacturer should periodically review performance, safety and the benefit-risk assessment for the medical device through a clinical evaluation, and update the clinical evidence accordingly.
The use of databases in medical device clinical trials
The variations in the available evidence-base for devices means that, unlike with drugs, medical devices will typically require the consideration and analysis of data from observational studies in ascertaining their clinical and cost-effectiveness. Using modern observational databases has advantages because these databases represent continuous monitoring of the device in real-life practice, including the outcome (Maresova et al., 2020).
Bayesian methods as an alternative framework for evaluation
Bayesian methods for the analysis of trial data have been proposed as an alternative framework for evaluation within the FDA’s Center for Devices and Radiological Health. These methods provide flexibility and may make them particularly well suited to address many of the issues associated with the assessment of clinical and economic evidence on medical devices, for example, learning effects and lack of head-to-head comparisons between different devices.
Use of placebo in medical vs pharmaceutical trials
An additional key difference between drug and medical device trials are that use of placebo in medical device trials are rare. If placebo is used in a trial for surgical / implanted devices it would usually be a sham surgery or implantation of a sham device (Taylor and Iglesias, 2009). Sham procedures are high risk and may be considered unethical. Without this kind of control, however, there is in many cases no sure way of knowing whether the device is providing real clinical benefit or if the benefit experienced is due to the placebo effect.
Conclusion
In conclusion, there are many similarities between medical device and pharmaceutical clinical trials, but there are also some really important differences that one should not miss:
- In general medical device clinical trials are smaller than drug trials.
- The research is mostly undertaken by SME’s ( small to medium enterprises) instead of big well-known companies
- Drugs interact with biochemical pathways in human bodies whereas medical devices use a wide range of different actions and reactions, for example, heat, radiation.
- Medical devices can be used for not only diagnostic purposes but therapeutical purposes as well.
- The use of placebo in medical device trials are rare in comparison to pharmaceutical clinical trials.
References:
Bokai WANG, C., 2017. Comparisons of Superiority, Non-inferiority, and Equivalence Trials. [online] PubMed Central (PMC). Available at: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5925592/> [Accessed 28 February 2022].
Chen, M., Ibrahim, J., Lam, P., Yu, A. and Zhang, Y., 2011. Bayesian Design of Noninferiority Trials for Medical Devices Using Historical Data. Biometrics, 67(3), pp.1163-1170.
E, L., 2008. Superiority, equivalence, and non-inferiority trials. [online] PubMed. Available at: <https://pubmed.ncbi.nlm.nih.gov/18537788/> [Accessed 28 February 2022].
Gubbiotti, S., 2008. Bayesian Methods for Sample Size Determination and their use in Clinical Trials. [online] Core.ac.uk. Available at: <https://core.ac.uk/download/pdf/74322247.pdf> [Accessed 28 February 2022].
U.S. Food and Drug Administration. 2010. Guidance for the Use of Bayesian Statistics in Medical Device Clinical. [online] Available at: <https://www.fda.gov/regulatory-information/search-fda-guidance-documents/guidance-use-bayesian-statistics-medical-device-clinical-trials> [Accessed 28 February 2022].
van Ravenzwaaij, D., Monden, R., Tendeiro, J. and Ioannidis, J., 2019. Bayes factors for superiority, non-inferiority, and equivalence designs. BMC Medical Research Methodology, 19(1).