
Part 1: Basket & Umbrella Trial Designs
Introduction
As the clinical research landscape becomes ever more complex and interdisciplinary alongside an evolving genomic and biomolecular understanding of disease, the statistical design component that underpins this research must adapt to accommodate this. Accuracy of evidence and speed with which novel therapeutics are brought to market remain hurdles to be surmounted.
While efficacy studies or non-inferiority clinical trials in the drug development space traditionally only included broad disease states usually with patients randomised to a dual arm of new treatment compared to an existing standard treatment. Due to patient biomarker heterogeneity, effective treatments could be left unsupported by evidence. Similarly treatments found effective in a clinical trial don’t always translate to show real world effectiveness in a broader range of patients.
Our current ability to assess individual genomic, proteomic and transcriptomic data and other patient bio-markers for disease, as well as immunologic and receptor site activity, has shown that different patients respond differently to the same treatment and, the same disease may benefit from different treatments in different patients – thus the beginnings of precision medicine. In addition to this is the scenario where a single therapeutic may be effective against a number of different diseases or subclasses of a disease based on the agent’s mechanism of action on molecular processes common to the disease states under evaluation.
Master protocols, or complex innovative designs, are designed to pool resources to avoid redundancy and test multiple hypotheses under one clinical trial, rather than multiple clinical trials being carried out separately over a longer period of time.
Due to this fairly novel evolution in the clinical research paradigm and also due to inherent flexibility within each study design, conflicting information related to the definition and characterisation of master protocols such as basket and umbrella clinical trials as well as cases in the published literature where the terms “basket” and “umbrella” trials have been used interchangeably or are ill-defined exists. For this reason a brief definition and overview of basket and umbrella clinical trials is included in the paragraphs that follow. Based on systematic reviews of existing research it seeks the clarity of consensus, before detailing some key statistical and operational elements of each design.

Basket trial:
A basket clinical trial design consists of a targeted therapy, such as a drug or treatment device, that is being tested on multiple disease states characterised by a common molecular process that is impacted by the treatment’s mechanism of action. These disease states could also share a common genetic or proteomic alteration that researchers are looking to target.
Basket trials can be either exploratory or confirmatory and range from full randomised, controlled double-blinded designs to single arm designs, or anything in between. Single arm designs are an option when feasibility is limited and are more focused on the pre-clinical stage of determining efficacy or whether a particular treatment has clear-cut commercial potential evidenced by a sizable enough retreat in disease symptomology. Depending on the nuances of the patient populations being evaluated final study data may be analyses by pooling disease states or by each disease state separately. Basket trials allow drug development companies to target the lowest hanging fruit in terms of treatment efficacy, focusing resources on therapeutics with the highest potential of success in terms of real patient outcomes.
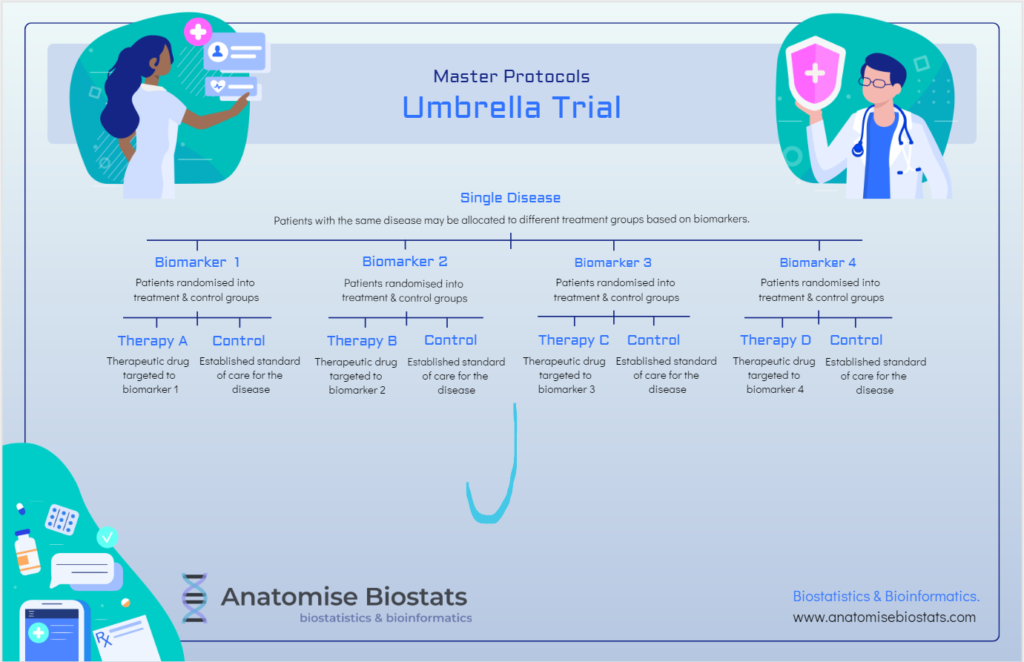
Umbrella trial:
An umbrella clinical trial design consists of multiple targeted treatments of a single disease where patients can be sub-categorised into biomarker subgroups defined by molecular characteristics that may lend themselves to one treatment over another.
Umbrella trials can be randomised, controlled double-blind studies that in which each intervention and control pair is analysed independently of other treatments in the trial, or where feasibility issues dictate, they can be conducted without a control group with results analysed together in-order to compare the different treatments directly.
Umbrella trials may be useful when a treatment has shown efficacy in some patients and not others, they increase the potential for confirmatory trial success by honing in on patient sub-populations that are most likely to benefit due to biomarker characteristics, rather than grouping all patients together as a whole.
Basket & Umbrella trials compared:
Both basket and umbrella trials are typically biomarker guided. The difference being that basket trials aim to evaluate tissue-agnostic treatments to multiple diseases based on common molecular characteristics, whereas umbrella trials aim to evaluate nuanced treatment approaches to the same disease based on differing molecular characteristics between patients.
Biomarker guided trials have an additional feasibility constraint to non-biomarker guided trials in that the size of the eligible patient pool is reduced in proportion to the prevalence of the biomarker/s of interest within that patient pool. This is why master protocol methodology becomes instrumental in enabling these appropriately complex research questions to be pursued.
Statistical Concepts and considerations of basket and umbrella Trials
Effect size
Basket and umbrella trials generally require a larger effect size than traditional clinical trials, in order to achieve statistical significance. This is in a large part due to the smaller sample sizes and higher variance that comes with that. While patient heterogeneity in terms of genomic or molecular diversity, and thus expected treatment outcome, has been reduced by the precision targeting of the trial design, there is a certain degree of between-patient heterogeneity that can only be expected when relying on treatment arms of very small sample sizes.
If resources, including time, are tight then basket trials enable drug developers to focus on less risky treatments that are more likely to end in profitability. It should be noted that this does not always mean that the treatments that are rejected by basket trials are truly clinically ineffective. A single arm exploratory basket trial could end up rejecting a potential new treatment that, if subject to a standard trial with more drawn out patient acquisition and a larger sample size, would have been deemed effective at a narrower effect size.
Screening efficiency
If researchers carry out separate clinical studies for each biomarker of interest, then a separate screening sample needs to be recruited for each study. The rarer the biomarker, the larger the recruited screening sample would need to find enough people with the biomarker to participate in the study. This number needs to be multiplied by the number of biomarkers. A benefit of master protocols is that a single sample of people can be screened for multiple biomarkers at once, greatly reducing the required screening sample size.
For example, researchers interested in 4 different biomarkers could collectively reduce the required screening sample by three quarters compared to conducting separate clinical studies for each biomarker. This maximisation of resources can be particularly helpful when dealing with rare biomarkers or diseases.
Patient allocation considerations
If relevant biomarkers are not mutually exclusive a patient could fit into multiple biomarker groups for which treatment is being assessed in the study. In this scenario a decision has to be made as to which category the patient will be assigned and the decision process may occur at random where appropriate. If belonging to two overlapping biomarker groups is problematic in terms of introducing bias in small sample sizes, or if several patients have the same overlap, then a decision may be made to collapse the two biomarkers into a single group or eliminate one of the groups. If a rare genetic mutation is a priority focus in the study then feasibility would dictate that the patient be assigned to this biomarker group.
Sample Size calculations
Generally speaking, sample size calculation for basket trials should be based on the overall cohort, whereas sample size calculations for umbrella trials are typically undertaken individually for each treatment.
Basket and umbrella trials can be useful in situations where a smaller sample size is more feasible due to specifics of the patient population under investigation. Statistically designing for this smaller sample size typically comes at the cost of necessitating a greater effect size (difference between treatment and control) and this translates to lower overall study power and greater chance of type 1 error (false negative result) when compared to a standard clinical trial design. Despite these limitations master protocols such as basket or umbrella trials allow to evaluation of certain treatments to the highest possible level of evidence that otherwise might be too heterogeneous or rare to evaluate using a traditional phase II or III trial.
Randomisation and control
Randomised controlled designs are recommended for confirmatory analysis of an established treatment or target of interest. The control group typically treats patients with the established standard of care for their particular disease or, in the absence of one, placebo.
In master basket trials the established standard of care is likely to differ by disease or disease sub-type. For this reason it may be necessary for randomised controlled basket trials pair a control group with each disease sub-group rather than just incorporating a single overall control group and potentially pooling results from all diseases under one statistical analysis of treatment success. Instead it is worth considering if each disease type and corresponding control pair could be analysed separately to enhance statistical robustness in a truly randomised controlled methodology.
Single arm (non-randomised designs) are sometimes necessary for exploratory analysis of potential treatments or targets. These designs often require a greater margin of success (treatment efficacy) to be statistically significant as a trade-off for a smaller sample size required.
Blinding
To increase the quality of evidence, all clinical studies should be double blinded where possible.
To truly evaluate the effectiveness of a treatment without undue bias from a statistical perspective double-blinding is recommended.
Aside from increased risk of type 2 error that may be inherent in master protocol designs, there is a greater potential for statistical bias to be introduced. Bias can introduce itself in a myriad of ways and results in a reduction in the quality of evidence that a study can produce. Two key sources of bias are lack of randomisation (mentioned above) and lack of blinding.
Single armed trials do not include a control arm and therefore patients cannot be randomised to a treatment arm where double-blinding of patients, practitioners, researchers and data managers etc will prevent various types of bias creeping in to influence the study outcomes. With so many factors at play it is important not to overlook the importance of study blinding and implement it whenever feasible to do so.
If the priority is getting a new treatment or product to market fast to benefit patients and potentially save lives, accommodating this bias can be a necessary trade-off. It is after-all typically quite a challenge to have clinical data and patient populations that are at homogeneous and matched to any great degree, and this reality is especially noticeable with rare diseases or rare biomarkers.
Biomarker Assay methodology
The reliability of biologic variables included in a clinical trial should be assessed, for example the established sensitivity and specificity of particular assays needs to be taken into account. When considering patient allocation by biomarker group, the degree of potential inaccuracy of this allocation can have a significant impact on trial results, particularly when there is a small sample size. If the false positive rate of a biomarker assay is too high this will result in the wrong patients qualifying for treatment arms, in some cases this may reduce the statistical power of the study.
A further consideration of assay methodology pertains to the potential for non-uniform bio-specimen quality at different collection sites which may bias study results. A monitoring framework should be considered in order to mitigate this.
Patient tissue samples required for assays, can inhibit feasibility and increase time and cost in the short term and make study reproducibility more complicated. While this is important to note these techniques are in many cases necessary in effectively assessing treatments based on our contemporary understanding a many disease states such as cancer within the modern oncology paradigm. Without incorporating this level of complexity and personalisation into clinical research it will not be possible to develop evidence based treatments that translate into real-world effectiveness and thus widespread positive outcomes for patients.
Data management and statistical analysis
The ability to statistically analyse multiple research hypotheses at once within a single dataset increases efficiency at the biostatisticians end and allows frameworks for greater reproducibility of the methodology and final results, compared to the execution and analysis of multiple separate clinical trials testing the same hypotheses. Master protocols also enable increased data sharing and collaboration between sites and stakeholders.
Deloitte research estimated that master protocols can save clinical trials 12-15% in cost and 13-18% in study duration. These savings of course apply to situations where master protocols were a good fit for the clinical research context, rather than to the blanket application of these study designs across any or all clinical studies. Applying a master protocol study design to the wrong clinical study could actually end up increasing required resources and costs without benefit, therefore it is important to assess whether a master protocol study design is indeed the optimal approach for the goals of a particular clinical study or studies.

References:
Lai TL, Sklar M, Thomas, N, Novel clinical trial solutions and statistical methods in the era of precision medicine, Technical Report No. 2020-06, June 2020